



TfT Performance: Roam Research
Our first competitor enters the stage. It's Roam Research - one of the veterans of the Tools for Thought scene. Let's get ready to rumble...

Hej,
And welcome to the Benchmark Results of Roam Research. Roam Research is considered by many to be the gold standard in tools for thought and has a large following.

If you are new here, you may want to read:

and
before you dive into this article.
Side note
I created the following videos essentially for me to measure the times quickly. I've linked them here to prove the results, but they're probably pretty dull despite being partly time-lapse.
All the diagrams I show here use the same color scheme and order—Blue for the 2,000 data set, turquoise for the 5,000, and green for the 10,000.
And please remember: We focus here exclusively on the performance figures of some operations. These may be entirely irrelevant for your use case. Also, the numbers say nothing about the tool's other capabilities - so please take the results with a grain of salt.
Importing Files
We start our benchmark by importing the files. If you look at the videos, you will see that I had twice an out-of-memory error with Roam Research, so I had to split the import into four smaller chunks and restart the application after the first three imports.
There should be better error handling than this, as it leaves the system in an unclear state. Roam Research imported some of the pages, some not. The application does not help identify the missing ones (e.g., using a log). Also, a rollback is not possible. In addition, all backlinks were missing from the imported pages.
I had the opportunity to restart entirely from scratch with an empty database, but that would not have been an option if there had already been data before the import.
The final runtime results show that the import times seem to scale linear with the number of imported pages, so we have an O(n) runtime complexity.

I don't see import times as a relevant factor since you rarely need this function. However, as the amount of data is tiny with less than 100 MB, I would expect shorter times.
2,000 Pages
5,000 Pages
10,000 Pages // Failed #1
10,000 Pages // Failed #2
10,000 Pages // Finally successful
Application Starting Times
Application start times are more critical than import times. Long loading times can be pretty annoying, and I know what I'm talking about since my computer career started with a C64 with a 5.25" floppy drive (Load "Donkey",8,1).
Roam Research takes between 10 and 14 seconds which I think is pretty long (and I haven't found a fast loader yet ;)). The time does not seem to scale with the size of the graph; it seems we have a complexity of O(1) here.
You can see the start times in the different videos at the beginning of each video.

Heavy Duty: Searching and references
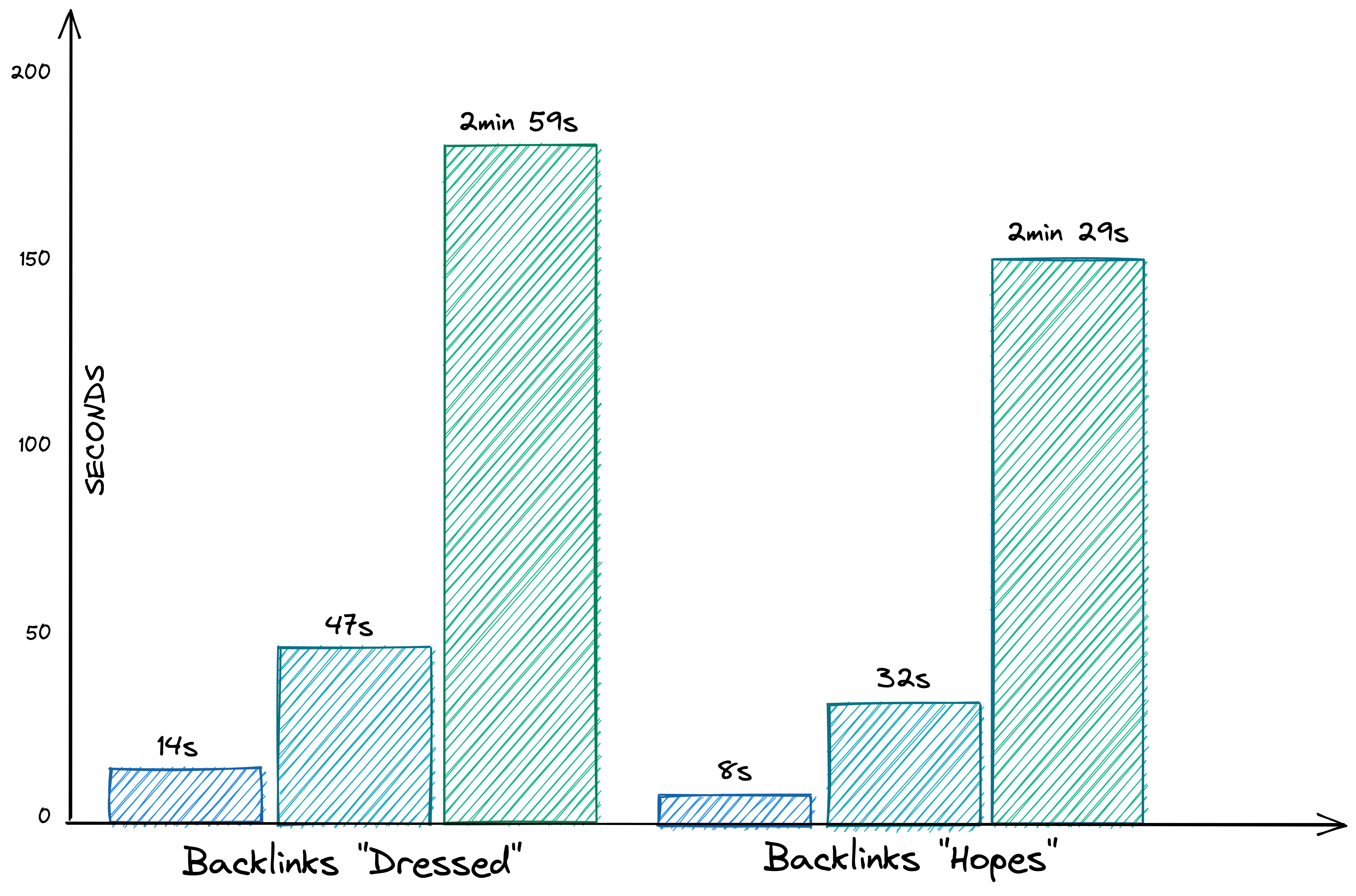
One of the most interesting tasks is loading pages with many backlinks. The page “dressed” has around 2,000, 5,000, and 10,000 backlinks (counting every link to this page, not just the first one on a page) for the different test data sets. “Lifted” has 1,250, 3,100 and 6,150, “Hopes” 1,100, 2,600 and 5,200 backlinks.
The load times mainly scale linearly with the number of backlinks (O(n)).
Load times are getting annoying on larger pages, but it’s acceptable.

Opening the references offers an exciting insight; load times now seem to scale exponentially with the number of backlinks or pages (O(n²)). This runtime complexity could be why in reality, with Roam Research, you quickly get into situations where opening the backlinks takes an uncomfortably long time (e.g., TODO or DONE).
You don’t want to work a lot with the references of the 10,000 pages data set.
2,000 Pages
5,000 Pages
10,000 Pages
Alice in Wonderland: Adding content and exporting
As you would expect, pasting content into the database does not depend on its size. We have a complexity measure of O(1) regarding the number of pages and backlinks.
Therefore when you are adding new content, the size of the database is not important at all. Roam Research is quite snappy here.
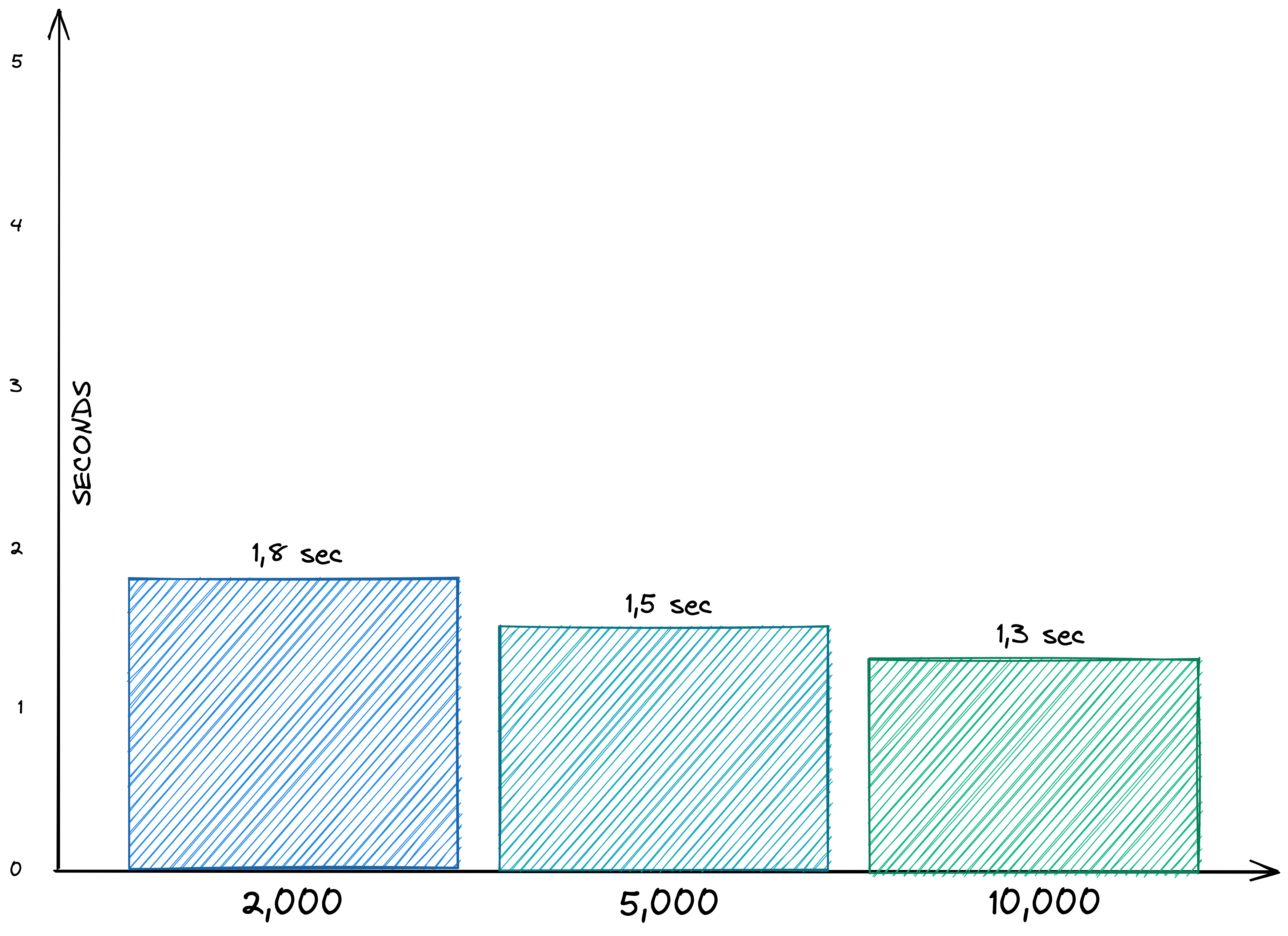
The time needed for exporting all pages in Markdown format scales with the number of pages (and their size). So the complexity measure seems to be O(n).
Like import, export is nothing you will frequently use, so times aren’t crucial here.

2,000 Pages
5,000 Pages
10,000 Pages
Bonus round: Filters and queries to the rescue
One often suggested solution for working with big pages is using filters and queries to reduce the data load. As you can see in the video, the filter will not reduce the page's load time. Instead, it seems to increase it a bit. But will dramatically improve loading the (now less) backlinks.
On the other hand, queries are fast and can be used without problems even with the amount of data, as long as the inheritance is not too large. Therefore, you should avoid working directly with the references and highly-linked pages and instead use appropriate queries.
Chrome M1 or desktop app?
Roam Research has optimized their Desktop app only for Intel processors, and a version for Apple M1 is not yet available. To examine whether it would make a difference, I compared the M1-optimized chrome browser with the desktop app.
And indeed, there seems to be a significant difference of 35 - 50 % with the 10,000 data set (load times of “dressed” were reduced from 3 minutes to 1:45 minute and loading “hopes” into the sidebar just took 1:35 min instead of 2:28 min). But using the Browser with such a large graph is quite annoying because of frequent “Page unresponsive” warnings.
Once an official M1 Desktop App is released, I will happily re-test Roam Research.
Conclusion
These are the results of the very first benchmark. Roam Research is still usable with the 10,000 pages data set, but you need good nerves when using the high-linked pages because the application keeps you waiting and jerks.
Application start times are high, and the failed imports are a no-go - remember to always do larger imports in batches. On the other hand, queries are surprisingly fast and a great tool for heavy data analysts.
Optimizations for the M1 processor will improve the performance but not by the needed orders of magnitude. I’m pretty sure that Roam Research will need some algorithmic enhancements to reduce the bottlenecks at references and backlinks because they will be even more dramatic the bigger the database (and the number of backlinks) gets.
However, we can only see what these values are worth when comparing them with those of the other applications. Therefore, you can look forward to the upcoming articles with me.
If you have any questions or suggestions, please leave a comment.
If you want to support my work, you can do this by becoming a paid member:
Or you can buy me a coffee ☕️. Thanks in advance.







Oh! So much great work and effort done here. Wondering how the comparison with other apps will look like. Thanks!
Hello 👋, thanks for that great article! Founder of https://roam-bot.com here :)
> The time does not seem to scale with the size of the graph; it seems we have a complexity of O(1) here.
To be exact, the loading time is more near O(n) with n being the graph size.
Because when RoamResearch loads it downloads the *whole* graph as a flat json file from https://firebasestorage.googleapis.com/v0/b/... you can confirm that when opening the network tab of the browser developer console.