
TfT Performance: Logseq
Open Source, mobile client, extensible, rapid development, that's Logseq. But can it stand up to the demands of my field test and how does it compare to Roam Research?

Hej,
And welcome to the Benchmark Results of Logseq, an (mainly) open-source outlining App with support for various operating systems including mobile. Logseq has made huge progress in the past few months and has gathered a large fan base around it.
If you are new here, you may want to read this first:

and
before you dive into this article. Also, the results of Roam Research may be interesting for you, although I will definitely summarize everything again at the end of all the tests.
Side note
I created the following videos essentially for me to measure the times quickly. I've linked them here to prove the results, but they're probably pretty dull despite being partly time-lapse.
All the diagrams I show here use the same color scheme and order—Blue for the 2,000 data set, turquoise for the 5,000, and green for the 10,000. For Logseq, I had to add a 7,500 pages data set in orange because the 10,000 group was too big to handle.
And please remember: We focus here exclusively on the performance figures of some operations. These may be entirely irrelevant for your use case. Also, the numbers say nothing about the tool's other capabilities - so please take the results with a grain of salt.
Importing Files
Importing the files gave me some headaches. The time required was OK (but not fast if you remember the import is less than 100 MB). But the large data set brought Logseq into trouble. Whether I import them in one big JSON file, many small ones (with restarting the App in between), or even as thousands of small Markdown files-10,000 always kill the App. With this kind of interconnectedness, I've reached the limit of what Logseq can currently handle.
However, under no circumstances should an application die with a white screen. Here, developers must take precautions and stop before the event happens and point out the error situation ("Houston, we are running low on memory").
Even worse, the 10,000-set made Logseq unusable. Every time I tried to start the application, the window turned white before I could do anything—a simple way to drive the average user into frustration. I finally fixed the situation by deleting a hidden configuration directory (the .logseq directory in your home directory).
The App should recognize when it has not started successfully (e.g., placing a small file at the beginning and deleting it when the startup process is successful. Logseq should initiate a recovery procedure (e.g., not loading a vault) if it is still there at the next start. That could also help with malfunctioning plugins).
Nevertheless, with Logseq, the situation is not a total disaster since the files are stored as text files in the file system, and can the user can access them via other means (but again, not too easy for the average Joe).
These problems are the reason for adding a 7,500 pages vault.

2,000
5,000
7,500
10,000 - Failed #1
10,000 - Failed #2
10,000 - Failed #3
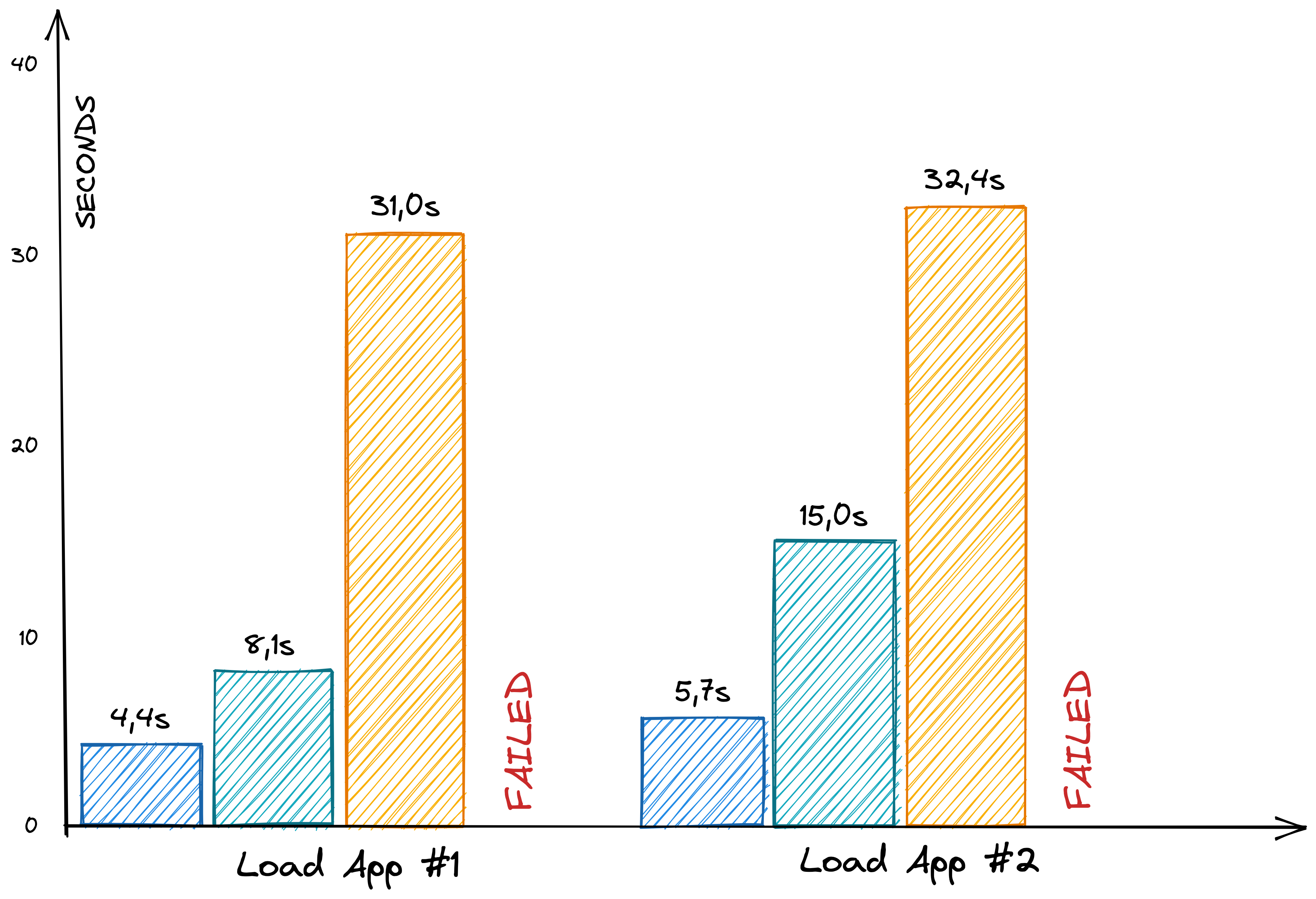
Application Starting Times
The start times for Logseq with small graphs are a big highlight. Logseq opens almost instantly (I measured the time until the journal page accepted inputs). But the time increases exponentially with larger graphs (that's different from how Roam Research behaved). More than 30 seconds for the 7,500-pages data set are way too much.
As already written above, I could not test the 10,000-pages graph.
Heavy Duty: Searching and references
Loading the high-grading linked pages is Logseq's parade discipline. Loading the "Dressed" page (6950 backlinks) was almost instantaneous. Even with the other pages in the sidebar, times were good on small data sets, but they grew fast the more extensive the database became.

Logseq also managed to load the backlinks quite quickly. In addition, scrolling in the application was smooth even with many references (something where Roam Research occasionally jerked). I think that opening the relations from "Hopes" while the connections from "Dressed" were already open hit a memory limit on the 7,500-pages database, which increased the time exponentially.

2,000
5,000
7,500
Alice in Wonderland: Adding content and exporting
As you would expect, pasting content into the database does not depend on its size. We have a complexity measure of O(1) regarding the number of pages and backlinks.
Therefore when you are adding new content, the size of the database is not important at all. Logseq is fast here.

Exporting was not as fast as in Roam Research but still fast enough in my opinion. It would be great if the user had any indication of how long the process will take.

2,000
5,000
7,500
Bonus round: Filters and queries to the rescue
Filters are not very useable right now on large databases. The filter dialog takes some time to load and because you can't search for terms (unlike in Roam Research) is nearly unusable. Once Logseq added a search function to the dialog, no more than the top 20 terms should be loaded and updated in real-time as soon as the user starts to enter a few characters.
On the other hand, queries are fast. The syntax is a bit unexpected and caused misunderstandings for me at first. Being able to switch between a table view and the reference view is excellent. Logseq should shorten the result texts because the table gets very wide soon.
Chrome M1 or desktop app?
Logseq provides an M1-optimized desktop application, which I have used for these tests. Unfortunately, the browser app crashed after a bit of time loading the vault (that worked with the desktop app). Again, this should not happen, and I have no explanation for why the browser can't do what the desktop app can.
Conclusion
I have mixed feelings about the performance of Logseq. Opening the App and pages was fast (almost instant) on smaller graphs, but that changed rapidly when the database grew bigger. I haven't thought that 10,000 pages would render Logseq unusable; they should look into this and try to identify if they can improve the memory usage and take precautions for dead-locks like the one I described above.
On the other hand, despite the loading times, the UI felt very snappy and fluid and made you forget that it is not a native app.
We see shorter times on app loading, page loading, and importing (especially on smaller data sets) compared to Roam Research. Still, the performance is significantly worse with larger data sets (up to the crash).
I see great potential for Logseq if they take care of their fundamentals.
In the following article, we briefly leave the outliners and look at Obsidian, a relatively new, modern application built by the team behind Dynalist. Perhaps the different architecture will handle the big data better?
If you have any questions or suggestions, please leave a comment.
If you want to support my work, you can do this by becoming a paid member:
Or you can buy me a coffee ☕️. Thank you so much for your attention and participation.
I did recently import 13K pages graph in Logsec on M1 Mac. It did take much time ( may be because of many linked refrences). Thought, it was bit slow, but imported all pages.
I find the UI very sluggish and not snappy at all, both at work and on my high-performance machine. That said, I'm now addicted to Logseq and don't want to move away. Maybe if they move from Electron to something like Tauri, it could help.