
TfT Performance: Machine Room
In the meantime - in the engine room - I have thought about the benchmark procedure and made necessary preparations.

Hej and welcome to this small interlude, where I talk about the task course, test data, test environment, and some pitfalls with formats and import limits before diving into the first results.
Preface
I've been thinking a lot about how to evaluate the performance of the tools best. In everyday use, you rarely come up against limits. And whether an application starts in 0.3 or 0.6 or 1.1 seconds or searching takes one or two blinks of an eye, it might be annoying but doesn't get us anywhere (and is hard to measure reliably).
I was more concerned with how the applications behave when we have been actively collecting and linking information over many years.
My current everyday database has around 3,000 pages with roughly 500,000 words and 15.000 interconnections - I would consider it mediocre. So I thought I'd raise the bar a bit.
Test Data
In the last article, I already provided some background around the generated test data. The biggest of my current sets contains 10,000 pages and 9,330,186 words. These 10,000 pages have 189,172 internal links (around 19 per page).
To set this in relation to something you might know, let's take a look at the size of Wikipedia:
On the first of January 2022, Wikipedia had 6,432,524 pages with 4,029,071,074 words.
A study from 2015 from the University of Pittsburgh showed that there are more than 300 internal links on each article.
Therefore even the largest of my data set is a magnitude smaller than Wikipedia and way less inter-connected. To be precise, it's a factor of 1:500 or just 0.2% of Wikipedia's size.
The markdown test data has a compressed size of just 28 MB. That's comparable to 10 high-res images or 30 seconds of an HD video.
I could quickly generate way bigger sets, but as you will see, this is already a sufficiently large amount of data to make one or the other tool sweat. If it looks like we can get additional insights with larger data sets, I will consider that as well.
Applications in scope
I've chosen the following candidates to be on the shortlist, but the list might get longer in the coming weeks:
I will have a look at the following applications to see if exciting evaluations are also possible there:
If you know of any other app that I should evaluate, leave a comment below.
Test Environment
My main computer is a basic MacBook Pro 13-inch from 2020. It has a reasonably fast Apple M1 processor and a relatively tight memory configuration of 8 GB (shared with the video card).
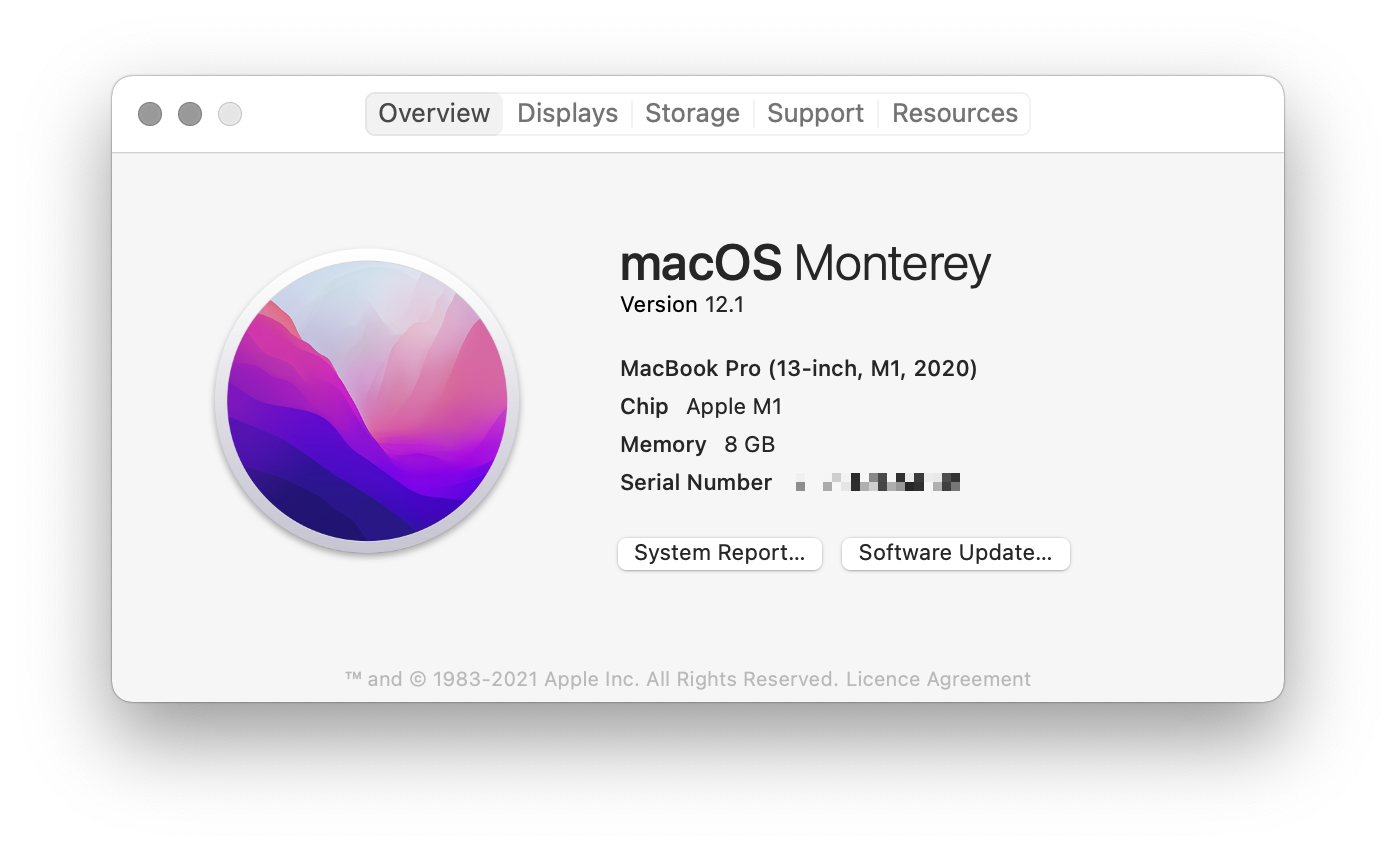
I use the latest desktop version for all programs in the test (if available). If there is a particular version for M1 processors, I chose this one.
No unnecessary programs were running during the benchmarks. Before starting the applications, I always cleared the memory (sudo purge).
Test course
I will look at three main tasks and two additional (depending on the functionality of the respective applications):
Import the test data (2,000 pages, 5,000 pages and 10,000 pages)
Navigate to the highest connected page and open the references (if not already done), then open the second and third highest pages in the sidebar or another window (if possible)
Create a new page and paste Chapter 1 of "Alice's Adventures in Wonderland" in it, then escape the rabbit hole by exporting the whole database as markdown files
Bonus Task (just done for the 10,000 pages graph):
Use filters to improve the performance of highly linked pages
Use queries to find the intersection pages of two prevalent words
I noticed a few things that I had to react to while preparing for the rest of the benchmarks.
Import Formats and Limits
We need various formats for all the different applications. Athens needs EDN Export from Roam Research, RemNote Zip-Archives of Markdown Files, Roam Research JSON or EDN Files, Logseq and Obsidian will eat raw markdown files stored in a directory. Some applications deny the import or even crash when the data is too big (remember what I said above about how small the data set is?).
I extended my python script to cover all of these factors; you can get the test data and experiment yourself.
What's next
I will start with the Benchmarks of Roam Research. I let Twitter decide which one will be next:
It may be essential for you to know that you are accompanying me on my benchmark journey, and I don't know the results yet either.
If you have any questions or suggestions, please leave a comment.
If you want to support my work, you can do this by becoming a paid member:
Or you can buy me a coffee. Thanks in advance.
Ivo Velitchkov suggested on Twitter adding Foam and Dendron to the list.