
Design Fixation: Why Your First Idea Is Your Worst Enemy
The cognitive paradox that AI quietly amplifies — and how to make AI break it instead

In 1991, the psychologists David Jansson and Steven Smith ran an experiment that every designer, engineer, and product manager should find unsettling. They gave participants a straightforward design task — create a spill-proof coffee cup — but to some groups, they also showed an example design. That example contained a flaw: a structural feature that any competent designer would spot. The researchers then asked all participants to generate as many original designs as possible.
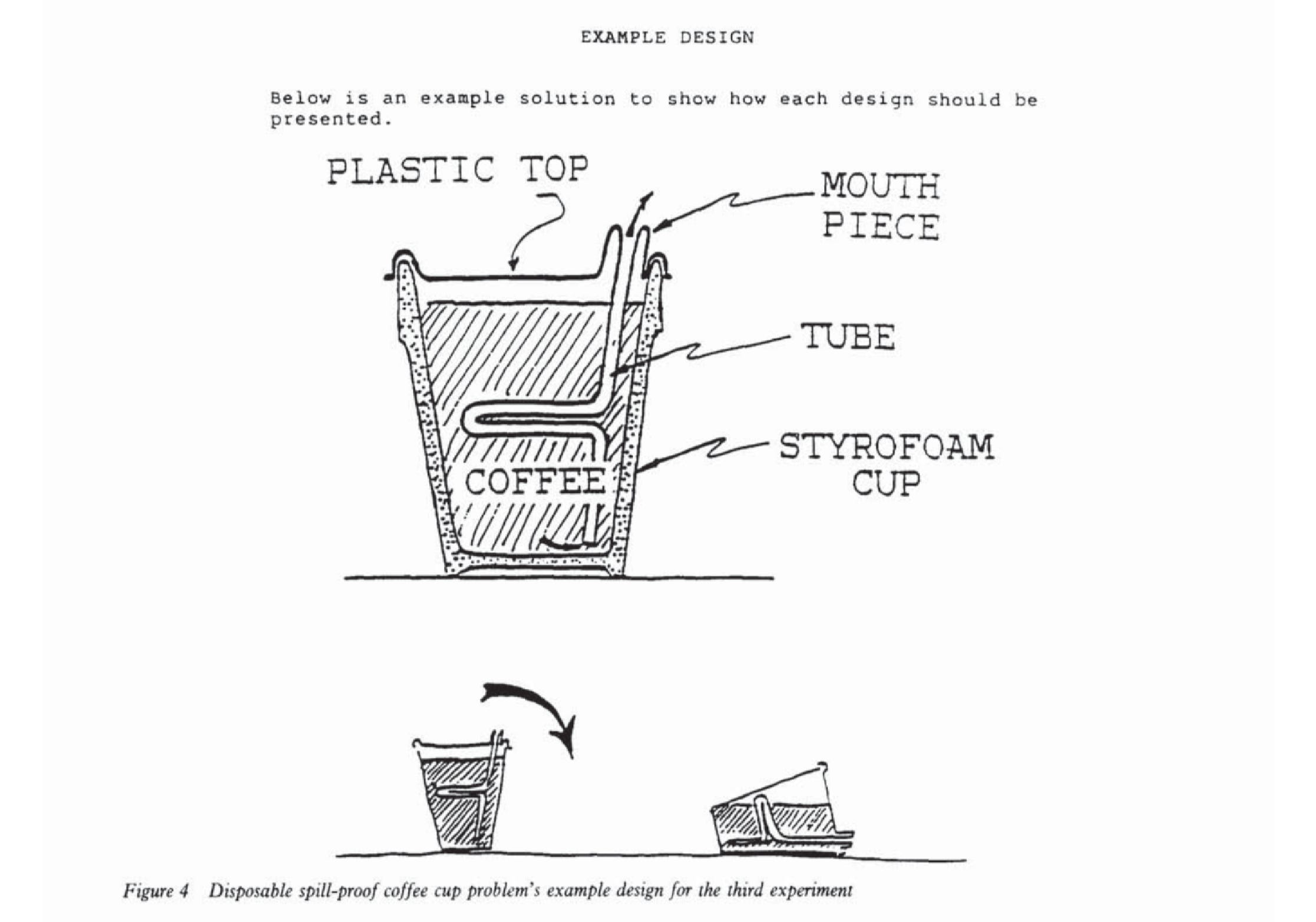
The participants who saw the flawed example did not avoid its flaw. They reproduced it — systematically, across multiple design generations, despite being told nothing about the example that should have constrained them. When Jansson and Smith published their results in Design Studies, they named a phenomenon that had been hiding in plain sight: design fixation — the blind adherence to a set of ideas or concepts that limits the output of conceptual design.
The paradox is as elegant as it is destructive: the very thing that enables creative work — a reference, a prototype, a first draft — becomes the invisible cage that contains it. You start with an idea, and the idea starts limiting you. You don’t notice because it looks like progress.
In 1991, this was a warning for design pedagogy. In 2026, with large language models embedded in nearly every creative and engineering workflow, it is a warning of a different magnitude — and, paradoxically, a clue to a solution that Jansson and Smith could not have anticipated.
The Paradox
Design fixation is not a failure of effort. It is a failure of awareness. The designer does not stubbornly insist on a bad idea — they never see the possibility space that exists beyond the idea they already have. The mind latches onto the first workable solution and treats it not as one option among many, but as the shape of the problem itself.
This puts design fixation at the center of a family of cognitive phenomena that have been studied for over eighty years, each describing a different facet of the same underlying mechanism.
In 1942, Abraham Luchins demonstrated the Einstellung effect — the mechanization of thought — using a deceptively simple task. Participants were given three water jugs of different capacities and asked to measure a specific volume. After solving several problems that required the same three-step procedure, they were given a problem that could be solved with a simpler two-step method. Most participants never saw the shortcut. Their minds had settled into a groove and refused to climb out. When Luchins later explicitly told participants, “Don’t be blind,” more than half immediately found the simpler solution. They were not incapable. They were fixated.
Even earlier, in 1935, the Gestalt psychologist Karl Duncker identified functional fixedness — the inability to see an object’s potential beyond its conventional use. In his famous candle problem, participants were given a candle, a box of thumbtacks, and a book of matches and asked to mount the candle on a wall without letting any wax drip onto the floor. The solution — empty the box, tack it to the wall, and use it as a platform — was nearly invisible to most participants because they could not see beyond the box’s function as a tack container. When the same box was presented empty, the solution rate doubled.
The common architecture across these phenomena is this: prior exposure to a solution, a method, or a function creates a mental groove so deep that alternative paths become cognitively invisible. The irony is that this mechanism is broadly adaptive — expertise is, in part, the efficient retrieval of known solutions. The cost is that expertise can become its own ceiling.
The AI Amplifier
The most straightforward way AI amplifies design fixation is by presenting a fluent, confident solution before the human has formulated one independently. An LLM’s default mode — when queried with a standard prompt at default settings — is to produce the statistically most probable continuation. It converges toward the centroid of its training distribution. The output arrives in seconds, in polished prose, and functions as a powerful cognitive anchor.
The anchoring effect, documented extensively by Tversky and Kahneman, is one of the most robust findings in behavioral economics: initial reference points shape subsequent judgments even when they are explicitly known to be arbitrary. An AI-generated first answer provides that initial reference point. Subsequent thinking adjusts from it, not from a blank slate.
This is not hypothetical. The Wharton study by Shaw and Nave on Cognitive Surrender — which I discussed in an earlier piece — found that 73% of participants followed an AI’s wrong answer without questioning it, even with no reason to trust it. Their confidence in wrong answers was higher than the confidence of participants who solved the same problems without AI. The fixating power of AI output is not just informational — it is rhetorical. Fluency is mistaken for validity.
And it scales. When a team member opens a design discussion with “I asked Copilot, and it suggested this,” the fixation propagates. The first AI-generated proposal becomes the shared anchor. In a 2024 study published in Organization Science, Boussioux and colleagues compared AI-generated solutions to crowd-generated solutions on a creative problem-solving challenge. Individually, the AI-generated ideas were rated as highly creative. But collectively, the AI-generated set was significantly less diverse than the human-generated set. The model produced excellent individual answers — but the answers converged. The AI did not just fixate one person. It narrowed the solution space for everyone who used it.
In the METR study of experienced open-source developers, I discussed in The Decomposition Gap, developers using AI tools took 19% longer to complete tasks they knew intimately — but felt 20% faster. The signature of cognitive capture: you feel fluent and productive while operating within a narrowed solution space.
The surface-level story is clear: AI, used naively, functions as a convergence engine. It produces the expected; the expected becomes the anchor, and the anchor limits the search. This is a real risk, and it is the risk that dominates most warnings about AI and creativity.
But it is not the whole story.
The Counterargument: AI as a Defixation Tool
The previous section described what happens when AI is used in its most passive mode: a single query, default parameters, and the first answer accepted as a proposal. This mode exists. It is common. But it is not the only mode, nor is it the one skilled practitioners use.
Large language models are not fixed-function convergence engines. They are controllable probability samplers whose parameters can be tuned to deliberately push the output toward the edges of the distribution rather than its center.
Temperature — a parameter that controls the randomness of token selection — is the most direct lever. At low temperatures, the model selects the most probable tokens, producing the “centroid” output described above. At high temperatures (typically above 1.0), the model assigns meaningful probability to lower-ranked tokens, producing more varied, less predictable, and often more surprising output. A model queried at temperature=1.2 or temperature=1.5 is not returning the expected answer. It is sampling from the less-traveled regions of its output space.
Negative prompting — instructing the model to avoid specific patterns, metaphors, or solution structures — can actively steer it away from the obvious. Telling a model “do not use a REST API,” “avoid the standard three-act structure,” or “do not propose a microservices architecture” forces it to sample from a deliberately constrained subset of its distribution. This is not a perfect mechanism — negative prompts are brittle, and models sometimes reproduce the forbidden pattern anyway —, but it is a mechanism that turns the model from a convergence tool into a divergence tool.
Persona adoption — asking the model to reason from an explicitly non-standard perspective — pushes in the same direction. “You are a physicist solving a design problem,” “you are a 14th-century cartographer describing a software system,” “you are an adversarial reviewer whose job is to find flaws in the following proposal.” These framing prompts, which are standard practice in advanced prompt engineering, do not eliminate fixation. But they can surface alternatives that a straightforward query would suppress.
The point is not that these techniques solve design fixation. They do not. The point is that the model is not the independent variable. The human’s steering of the model is. The same tool that amplifies fixation when used passively can be used actively to generate divergent alternatives, surface hidden assumptions, and probe the edges of a problem space.
This reframes the question. It is not “does AI cause design fixation?” The question is: under what conditions does AI amplify fixation, and under what conditions can it be used to resist it?
The answer, as with most things in the AI era, depends on the cognitive architecture the human brings.
What the Research Says About Breaking Fixation
If design fixation is the cognitive tax on creativity, what does the evidence say about breaking free — with or without AI?
The most robust finding across decades of research is that incubation works. In a meta-analysis published in Psychological Bulletin, Sio and Ormerod confirmed that taking a break from a problem — genuinely stepping away and engaging in an unrelated task — significantly increases the probability of overcoming fixation. The mechanism is not mystical. Incubation allows the mind to release the dominant solution path, making room for previously inhibited alternatives. The practical implication for AI-assisted work is straightforward: the most productive thing you can do after receiving an AI-generated solution may be to close the tab and do something else.
Analogical transfer — drawing on solutions from structurally similar but superficially different domains — consistently reduces fixation in experimental settings. Gick and Holyoak’s foundational work in Cognitive Psychology showed that exposing participants to an analogous problem from a different domain substantially increased solution rates on target problems. The AI-era implication: this is precisely the kind of prompting that a skilled user can direct the model to perform. “Find me three analogous problems from biology, urban planning, and game design” is a query that can surface structural parallels that are otherwise invisible within a single domain.
The generic parts technique, developed by McCaffrey (2012) in Psychological Science, offers a systematic defixation method. For any object or concept, repeatedly ask: “Does my description imply a use? If so, describe it more generically.” A candle wick becomes “a string,” which becomes “interwoven fibrous strands.” People trained in this technique solved 67% more problems than a control group that suffered from functional fixedness. The technique works because it systematically strips away the functional assumptions that constitute fixation.
And in a finding that directly echoes Luchins’ 1942 result, Chrysikou and Weisberg (2005) showed that explicit defixation instructions — telling people where the trap lies — significantly reduced fixation effects even when problematic examples were presented. Simply knowing about fixation helps.
What’s notable is that every one of these evidence-based defixation strategies can be operationalized in an AI-assisted workflow — but only if the human drives the process. The model will not spontaneously propose an incubation period. It will not, unprompted, draw an analogy to urban planning. It will not strip functional assumptions from a problem unless explicitly instructed to do so. The defixation work is done by the human working through the model, not by the model alone.
The Skill, Not the Tool
This brings the argument to a conclusion that is more nuanced than “AI makes us less creative” — and more useful.
Design fixation is a real cognitive phenomenon, experimentally established across decades and replicated across cultures. AI can amplify it. A default-temperature query for a solution produces a convergent answer that functions as a powerful cognitive anchor. Used passively, without deliberate counter-steering, the model narrows the solution space.
But AI can also be steered against fixation. Temperature, negative prompting, persona framing, and divergent querying — these are techniques that push the model toward lower-probability regions of its output space, surfacing alternatives that straightforward prompting suppresses. The model is not inherently a convergence engine. It becomes one when used in a particular way.
The decisive variable is the human’s cognitive architecture. The skill is not prompting in the narrow sense — not the syntactic optimization of query strings. The skill is the deliberate management of the creative process: generating independently before querying, steering toward divergence, delaying convergence in teams, building incubation into the workflow, and treating the model’s output as one input among many rather than as a terminus.
This is the same argument I made in The Decomposition Gap, applied to a different cognitive domain. The people who get more from AI are not those with the cleverest prompts. They are those who bring a deliberate structural approach to the problem — in this case, the discipline of resisting the natural human tendency to fixate on the first plausible solution, whether it comes from their own mind or from a model.
The first idea is not the best idea. It is just the one you saw first. And whether that first idea came from your own cognition or from a machine, the discipline of looking past it — of doubting it, decomposing it, generating alternatives to it — remains a human responsibility. A well-steered model can help. It cannot substitute.
This is the fourth in a series on cognitive skills in the AI era. Previous pieces: The Decomposition Gap, The Machine That Stops You From Thinking, and On the Art of Doubting.